

I think this is my best redesign because it solves the main problem in the original visualization - hard for the readers to distinguish the colors and to understand whether they represent candy score or characteristics of candy. So, by using shapes to represent the characteristics of candies, we now only use color to encode candy score, which makes the visualization easier to read.

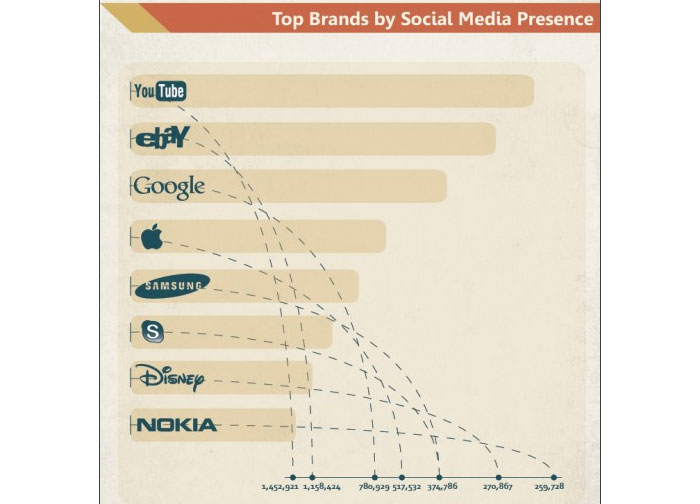
Marks:
[Rectangles] mark encodes [the amount of money].
Visual channels:
[position-y] channel encodes [the rank of the amount of money].
[color] channel encodes [the amount of money (the darker, the larger the amount)].
Who is the audience? The audiences for this visualization are people who read articles from Bloomberg, NYtimes, The Guardian, Washington Post, or World Bank. They may be interested in numbers behind the business world and market value behind companies like Apple. Also, the audiences may also be people who are passionate about social issues like income disparities and resource disparity between the 99% of people in the world and the top 1%.
Message and questions behind this visualization: The primary goal of this visualization is to give comprehensible meanings to big numbers, like 1 trillion. For example, it uses Apple’s market value to represent 1 trillion and 13 trillion to represent the US’s household debt. It uses the size of the squares to compare the different aspects, for example, the world GDP has a much bigger square than Apple’s market value, proportional to their actual sizes 1 trillion vs. 75.6 trillion. The secondary goal of this visualization is to emphasize the wealth discrepancies between the 99% of people in the world and the top 1%. As shown in the graph, the wealth of the top 1% is on the lower right corner, which means the top 1% has more money than the money in all the world’s central banks, the world GDP, and even the total global debt. This visualization emphasizes the huge problem of income inequality in the world and raises awareness for this issue.
What data is encoded in the visualization? Information on market value, GDP, debt, and wealth, and their corresponding values in trillions.
How does the visualization encode the data? The visualization encodes the data in the Trillion Dollar-o-Gram, which utilizes the sizes of squares to compare the values.
What tasks do readers perform on the visualization? Readers are able to compare values, gain an understanding of the relations between different aspects, and also identify the extreme (wealth of top 1%).
How are the five principles applied to this visualization? Truthful: The visualization is truthful since it showed the data in context using the sizes of the squares and disclosed the data source. Functional: The visualization was very easy to read, used accurate sizes of squares to represent numbers, and it supports the meaningful task: to provide context for large numbers. Beautiful: The font and color progression adopts minimalist design principles and is very easy to read. Also, it is free of unnecessary elements. Insightful: The visualization helped to confirm my belief in the wealth discrepancy in our society, but it revealed to me that the discrepancy is much larger than I thought. Enlightening: The visualization went beyond the numbers and insights. It raised awareness of socio-economic issues that exist in our society.
Why is this visualization good? As we talked about in class, context is very important when we want to represent data. This visualization provides the context for readers to understand what 1 trillion really means and how it compares to other important concepts like world GDP and wealth of the top 1%. It also raised awareness for the income and wealth gap between the 99% and top 1%.
Who is the audience? The main audience for this visualization is people working in the tech field or are interested in going into the tech field.
Message and questions behind this visualization: The visualization shows the gender and ethnic gap within the tech field. It shows the different groups of people working in major tech companies in the US and compares the numbers with the US population.
What data is encoded in the visualization? US population, the number of people (different groups: gender, ethnicity) working in the major tech companies in the US.
How does the visualization encode the data? It uses the horizontal bar chart.
What tasks do readers perform on the visualization? Readers are able to compare the population of different groups of people within a tech company with the US population. They can see that there are more male than female working in all of the major tech companies, and there is a higher percentage of Asians working in major tech companies compare to other ethnicities. It also allows readers to interact with the visualization by clicking on a column and the graph will be sorted according to that column.
How are the five principles applied to this visualization? Truthful: The visualization provides a context for the data. By comparing each number to the US population, it is very easy for readers to understand which group of people is well represented in the tech field. It also disclosed the data source. Functional: The visualization was very easy to read and clear. It not only uses the lengths of squares to represent the number of people but also included the actual number (in proportion) to make it easier for readers to compare. Beautiful: the color scheme of this visualization is very clean and beautiful with no “junks.” Also, it uses grey/black for the data for the US population, US congress, and so on, in order to emphasize the actual companies’ data in the middle. Insightful: The visualization is insightful because it gave meaning to the numbers by comparing them with the US population in general. It showed which companies are more diverse. On the other hand, I would like to learn more about the details in each ethnicity, for example, within Asians, what percent is Chinese American vs. Indo-American, which the graph did not show. Enlightening: The visualization showed interesting patterns about diversity in the tech field in the US, and it showed that some are better represented than others. By including data from previous years, the visualization is able to let the readers see the changes in minority representation in the tech field. On the other hand, it also can be misleading if readers interpret it incorrectly. For example, if all the increase in the Asian population went to Indo-Americans, we cannot say that the company was becoming more diverse. Thus, I believe the visualization can be better if it also represents the subgroups within each ethnicity.
Why is this visualization good? Although it has areas of improvement, I still believe this is a good visualization because it not only provides a great context for the data, but also is able to interact with users to rank according to different criteria (e.g. female, white)and track the changes across years. It provides insights into the gap between genders and different ethnicities that exist in the tech field.

Marks:
[Rectangles/bars] mark encodes [the number of people].
Visual channels:
[position-x] channel encodes [characteristics].
[position-y] channel encodes [companies].
[color] channel encodes [the number of people in each characteristics].

Marks:
[Areas] mark encodes [the amount of people consider a language as mother tongue].
Visual channels:
[values] channel encodes [the amount of people].
[color] channel encodes [languages].
Who is the audience? People who are interested in the topic of languages or are interested in learning different languages.
Message and questions behind this visualization: This visualization aims to provide the readers with a better understanding of the size of the 23 languages that are considered as mother tongue in the world. Also, it listed dialects within each language, the number of countries in which a language is spoken, and the most popular languages being learned in the world.
What data is encoded in the visualization? The number of languages that are considered mother tongue in the world. The number of people who consider a language as their mother tongue. The number of countries in which a language is spoken. The most popular languages being learned in the world. The count of the living languages used as the first language in 60 countries.
How does the visualization encode the data? The visualization utilizes the Voronoi Treemap to visualise hierarchical data and to show the weight of each one.
What tasks do readers perform on the visualization? The readers can learn about the 23 mother tongue languages that are currently being spoken in different countries. They can also learn about the dialects within each language. More importantly, they can compare the size of each area and see which languages are used as the mother tongue by more people.
How are the five principles applied to this visualization? Truthful: the visualization provided the data source and showed data in the context with the size of each area. Functional: the graph is very easy to read encodes the population for each language effectively with the sizes. Beautiful: the most important quality of this visualization is its beauty. The color scheme is well balanced and the fonts are also well-designed. Insightful: the visualization works the best when combined with the bar chart at the bottom. It showed the insight that although English is not the most-spoken first language, it is the language that is spoken in most countries. Enlightening: This visualization is able to inform the readers about the languages in different parts of the world. It also makes us feel connected and appreciated the diversity in the world.
Why is this visualization good? I believe this visualization is good because it presented the data in the full picture, by multiple visualization formats: bar graphs, the big cycle, and map. It was able to show different sides of the data, for example, the most popular languages, the number of countries a language was spoken, or the distribution of living languages. It gives readers a sense of union and appreciation for all the unique languages and cultures in the world.










{kind=link}
{kind=link}